Implémentation d'un lexique avec Objective Caml
Par
Edouard Evangelisti (Cameland) (Blog)
Cet article propose une implémentation efficace des lexiques avec Objective Caml.
Deux exemples d'application sont proposés : auto-complétion des mots au cours de la frappe, application
aux jeux de lettres (Boggle, anagrammes).
I. Quelques définitions
I-A. Mot
Dans cet article, un mot est défini comme une séquence de caractères de longueur non nulle.
Par caractère on entend les lettres minuscules et capitales d'imprimerie (portant ou non des signes
diacritiques), les chiffres et tous les caractères spéciaux, à l'exclusion des espaces. Il est possible
de retenir une définition plus restrictive, où serait exclus les caractères qui ne sont pas des lettres,
mais cela n'est pas nécessaire dans cet article.
I-B. Lexique et dictionnaire
Dans cet article, un lexique est défini comme un ensemble de mots. Il existe un lexique vide
ne comportant aucun mot. Un dictionnaire est un ensemble de mots auxquels sont associés des
données de nature quelconque. Il existe également un dictionnaire vide.
II. Représentation d'un lexique
Il existe plusieurs manières de représenter un lexique. L'une d'entre elles est particulièrement bien adaptée à une grande
variété de problèmes. Je vous propose de l'introduire à travers la mise en évidence de contraintes.
Contrainte de taille - Disons-le d'emblée : les lexiques que nous allons manipuler sont très volumineux :
ils comportent entre 300 et 600 000 mots. C'est suffisant pour déclencher
une erreur de débordement de pile (Stack_overflow). En effet, la pile d'OCaml est limitée, par défaut, à un peu plus de 260 000
appels. Cela suffit pour de petits lexiques, mais pas pour ceux que nous allons manipuler ici. La représentation que nous allons choisir
doit donc nous permettre d'insérer des mots sans engendrer ce type de comportement. En fait, on voudrait écrire une fonction d'insertion
dont la complexité en temps serait indépendante de la taille n du lexique.
Contrainte de stockage - Lorsqu'un lexique est utilisé pour stocker les mots d'une langue, le stockage séparé des mots est généralement
très redondant. Il existe en effet de nombreux préfixes communs à des familles entières de mots. On voudrait donc, si possible, trouver
un moyen de réduire cette redondance sans affecter pour autant les performances.
Contrainte de style - Nous allons essayer de représenter notre arbre de façon purement fonctionnelle, c'est-à-dire sans effectuer aucun
effet de bord. En d'autres termes, l'insertion d'un mot dans un lexique doit être une fonction qui crée un nouveau lexique, et non une
fonction qui ajoute un mot à un lexique existant, et ne renvoie aucune valeur.
III. Implémentation d'un lexique
Les différentes contraintes que nous avons présentées ci-dessus ne sont pas incompatibles. Il est en effet possible de les satisfaire toutes
en utilisant un arbre des préfixes ou prefix tree, encore appelé trie. Cet arbre est composé de noeuds qui présentent la structure
suivante
(voir Figure 1)
:
- Chaque noeud correspond à un caractère. Les caractères sont stockés sous forme de valeurs de type int, char,
string, etc. Nous en reparlerons ultérieurement.
- Un drapeau (généralement un booléen) indique, à chaque niveau de l'arbre, si les noeuds parcourus depuis la racine
forment un mot.
- Les noeuds supérieurs de l'arbre sont stockés sous forme de couples (clef, valeur). Plusieurs implémentations de es couples
peuvent être utilisées. Nous les présenterons plus tard.
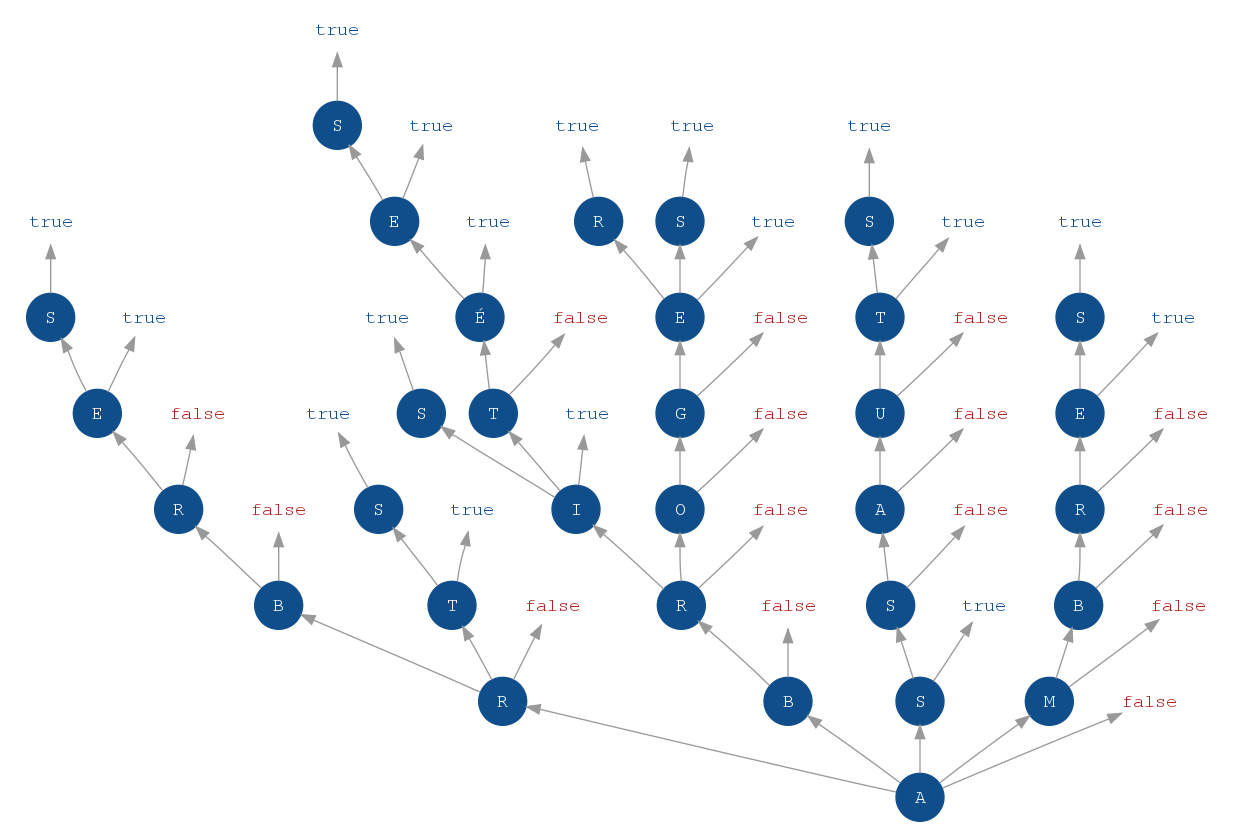
Figure 1 - Structure d'un arbre des préfixes
Notons d'emblée que cette structure permet d'obtenir rapidement l'ensemble des mots qui possèdent un préfixe donné ; cela revient en effet à
extraire le sous-arbre correspondant. Nous allons voir qu'il est également possible de satisfaire toutes les contraintes que nous avons énoncées
plus haut.
III-A. Fonctions de manipulation des mots
Avant toute chose, on suppose disponibles les fonctions suivantes :
- Fonction explode, qui scinde un mot en liste de caractères.
- Fonction compare, qui compare des caractères deux à deux.
La fonction compare est déjà disponible dans la bibliothèque standard d'OCaml : c'est Pervasives.compare. Il existe également
des versions spécialisées (String.compare, Char.compare), mais je préfère rester le plus général possible pour le moment.
explode n'est quant à elle pas disponible. Si l'on travaille exclusivement avec des caractères non accentués, on peut utiliser
la fonction suivante :
| Fonction explode |
let explode str =
let rec loop acc = function
| 0 -> acc
| i -> let j = i - 1 in loop (str.[j] :: acc) j
in loop [] (String.length str)
|
L'écriture de cette fonction est donnée seulement à titre d'exemple ; en effet, son écriture varie selon le codage des caractères
que l'on utilise. Ainsi, si les
chaînes de caractères sont codées en UTF-8, la fonction précédente, qui construit en quelque sorte une liste d'octets à partir d'une
chaîne, ne sera pas valable (l'hypothèse selon laquelle un octet correspond à un caractère n'étant alors pas toujours vérifiée).
III-B. Choix d'implémentation
Implémentation des couples (caractère, noeud) - L'implémentation des couples (caractère, noeud fils) peut se faire à l'aide d'un tableau
de 26 cases. Chaque case correspond alors à une lettre (la première case correspond au caractère 'a', la seconde à 'b', et ainsi de suite). Cette
représentation garantit un accès en temps constant (O(1)) au noeud fils. Elle présente cependant plusieurs défauts : tout d'abord, il n'est pas
possible d'utiliser des caractères pour lesquels aucune case n'a été prévue. Ensuite, lorsque le lexique comporte peu de mots, beaucoup de mémoire
est utilisée pour rien, puisque les cases ne pointent vers aucun noeud fils ! L'implémentation peut aussi faire appel à une liste d'association.
Cette méthode évite de gaspiller trop de mémoire et n'est pas limitée en nombre de caractères. Hélas, la recherche d'un noeud fils possède une
complexité en temps linéaire O(s) où s désigne la longueur de la liste. Les inconvénients liés à ces deux méthodes m'ont poussé à utiliser
une implémentation à base d'arbres binaires (module Map de la bibliothèque standard), qui permet une recherche du noeud fils en O(log s)
tout en conservant les avantages des listes par rapport aux tableaux.
Enfin, notons au passage qu'une table de hachage est aussi envisageable, mais qu'elle exclut tout tri des mots selon l'ordre lexicographique.
Représentation des caractères - La représentation des caractères est libre et correspond à un type t quelconque. Ceci nous permet
de conserver une grande généricité. Cela ouvre également la voie à l'écriture d'un foncteur qui accepterait le module suivant en entrée :
| Signature du module passé en argument au foncteur |
module type CHAR =
sig
type t
val compare : t -> t -> int
val explode : string -> t list
end
|
III-C. Le code OCaml
III-C-1. Type d'un lexique et lexique vide
Parmi les différentes solutions possibles, j'ai choisi d'utiliser
un type enregistrement (record) non mutable. Il présente l'avantage d'alléger les notations
par rapport à couple (en particulier dans les arguments des fonctions auxiliaires internes) :
| Type d'un lexique |
type t = { flag : bool; cmap : t CharMap.t }
|
Si InputModule désigne le module de type CHAR donné en argument au foncteur, alors
le module CharMap est défini de la façon suivante :
module CharMap = Map.Make(InputModule)
|
Ceci étant, la définition et la manipulation d'un lexique vide sont alors très faciles :
| Lexique vide |
let empty = { flag = false; cmap = CharMap.empty }
let is_empty lex = not lex.flag && CharMap.is_empty lex.cmap
|
III-C-2. Ajout d'un mot dans un lexique
L'ajout d'un mot dans un lexique consiste à progresser caractère par caractère dans
le lexique jusqu'à épuiser tous les caractères du mot ; à ce niveau, le drapeau flag
doit être redéfini comme étant égal à true. Si le mot à insérer n'est le préfixe
d'aucun autre mot déjà présent dans le lexique, la fonction CharMap.find lèvera
tôt ou tard l'exception Not_found. Dans ce cas, de nouveaux noeuds, initialement
vides, devront être insérés dans le lexique pour achever l'insertion.
| Ajout d'un mot |
let add str lex =
let rec loop lex = function
| [] -> { lex with flag = true }
| chr :: t ->
let res = loop (try CharMap.find chr lex.cmap with _ -> empty) t in
{ lex with cmap = CharMap.add chr res lex.cmap }
in loop lex (InputModule.explode str)
|
III-C-3. Appartenance d'un mot à un lexique
Pour tester l'appartenance d'un mot à un lexique, il suffit de progresser caractère
par caractère dans l'arbre afin de récupérer la valeur du drapeau associé au dernier
caractère du mot. Lorsque la fonction CharMap.find échoue prématurément, le mot
est absent du lexique.
| Test d'appartenance d'un mot |
let mem str lex =
let rec loop lex = function
| [] -> lex.flag
| chr :: t when CharMap.mem chr lex.cmap ->
loop (CharMap.find chr lex.cmap) t
| _ -> false
in loop lex (InputModule.explode str)
|
III-C-4. Supprimer un mot d'un lexique
Supprimer un mot d'un lexique consiste à redéfinir le drapeau associé au dernier caractère
du mot en lui assignant la valeur false. Mais attention, ce n'est pas si simple ! Il
faut aussi veiller à ne pas conserver les noeuds qui ne portent plus aucun mot. Ce point est
très important, sinon l'ajout d'un mot au lexique vide, suivi de sa suppression, ne redonnera pas
un lexique vide !
| Suppression d'un mot |
let rem str lex =
let rec loop lex = function
| [] -> { lex with flag = false }
| chr :: t when CharMap.mem chr lex.cmap ->
let res = loop (CharMap.find chr lex.cmap) t in
{ lex with cmap =
if is_empty res then CharMap.remove chr lex.cmap
else CharMap.add chr res lex.cmap }
| _ -> lex
in loop lex (InputModule.explode str)
|
III-C-5. Taille d'un lexique
La taille d'un lexique est définie comme le nombre de mots qui le composent.
Elle peut être obtenue de différentes manières plus ou moins lisibles
et performantes. Celle qui semble la plus intuitive utilise CharMap.fold ; c'est celle que
je vous présente ici (sachez qu'il en existe une autre plus efficace qui utilise des références
et CharMap.iter; elle n'est utile que si vous devez calculer très souvent la taille de très
gros lexiques).
| Taille d'un lexique |
let len lex =
let rec loop lex n =
CharMap.fold (fun _ -> loop) lex.cmap (n + if lex.flag then 1 else 0)
in loop lex 0
|
IV. Du lexique au dictionnaire
Jusqu'à présent, nous nous sommes intéressés à l'implémentation d'un lexique. Or il suffit de modifier
légèrement l'implémentation pour obtenir un dictionnaire. Les mots deviennent alors des clefs
auxquelles sont associées des données de type arbitraire. Pour y parvenir, nous allons adopter la
convention suivante : la valeur None correspond au booléen false, et la valeur Some
au booléen true, quelle que soit la valeur associée. Nous obtenons ainsi :
type 'a t = { flag : 'a option; cmap = 'a t CharMap.t }
|
V. Exemples d'application
V-A. Jeux de lettres
L'une des applications ludiques des lexiques concernent les jeux de lettres tels que le
Boggle ou la
recherche d'anagrammes.
Leur structure est en effet très adaptée à la recherche de mots. En particulier, elle permet d'éviter de nombreuses comparaisons inutiles
en décidant très rapidement d'interrompre une
recherche lorsqu'un préfixe est absent. C'est particulièrement vrai au Boggle, où essayer toutes les combinaisons qui satisfont les
contraintes du jeu dans une grille standard de 16 cases nécessite
plusieurs dizaines de secondes (il y a plus de 12 millions de combinaisons valides selon les règles du jeu). Je vous invite à consulter
les sources du logiciel OCamlBoggle (
https://sourceforge.net/projects/ocamlboggle/) pour voir comment les lexiques
peuvent être mis à profit dans ces situations.
Remarque : Ce petit logiciel est un bon exemple d'utilisation grandeur nature des lexiques puisqu'il utilise un base de données
de presque 610 000 mots. Il s'agit en fait d'un dictionnaire dans lequel les clefs sont les mots en majuscules et sans accents (ce qui
correspond donc aux lettres piochées dans une grille de Boggle); la valeur associée à une clef n'est autre que la liste des mots
accentués correspondants (par exemple, la clef PRATIQUE est associée à la liste ["pratique"; "pratiqué"]).
OCamlBoggle 1.1 - Jeu du Boggle
V-B. Applications bureautiques
Les logiciel de traitement de texte présentent souvent une fonctionnalité d'auto-complétion des mots au cours de la frappe. Certains
éditeurs de texte l'étendent aux commandes d'un langage de programmation et/ou de balisage (par exemples les commandes LaTeX). Dans tous les
cas, l'auto-complétion est grandement facilitée par la représentation des mots sous forme de trie : il suffit en effet d'extraire le sous-arbre
correspondant à un préfixe donné pour connaître toutes les suggestions en rapport avec le texte saisi !
VI. Code complet
| Fichier d'implémentation |
module type CHAR =
sig
type t
val compare : t -> t -> int
val explode : string -> t list
end
module type LEXICON =
sig
type t
val empty : t
val is_empty : t -> bool
val add : string -> t -> t
val mem : string -> t -> bool
val mem_prefix : string -> t -> bool
val rem : string -> t -> t
val len : t -> int
val sub : string -> t -> t
end
module Make (InputModule : CHAR) : LEXICON =
struct
module CharMap = Map.Make (InputModule)
type t = { flag : bool; cmap : t CharMap.t }
let empty = { flag = false; cmap = CharMap.empty }
let is_empty lex = not lex.flag && CharMap.is_empty lex.cmap
let add str lex =
let rec loop lex = function
| [] -> { lex with flag = true }
| chr :: t ->
let res = loop (try CharMap.find chr lex.cmap with _ -> empty) t in
{ lex with cmap = CharMap.add chr res lex.cmap }
in loop lex (InputModule.explode str)
let mem str lex =
let rec loop lex = function
| [] -> lex.flag
| chr :: t when CharMap.mem chr lex.cmap ->
loop (CharMap.find chr lex.cmap) t
| _ -> false
in loop lex (InputModule.explode str)
let mem_prefix str lex =
let rec loop lex = function
| [] -> true
| chr :: t when CharMap.mem chr lex.cmap ->
loop (CharMap.find chr lex.cmap) t
| _ -> false
in loop lex (InputModule.explode str)
let rem str lex =
let rec loop lex = function
| [] -> { lex with flag = false }
| chr :: t when CharMap.mem chr lex.cmap ->
let res = loop (CharMap.find chr lex.cmap) t in
{ lex with cmap =
if is_empty res then CharMap.remove chr lex.cmap
else CharMap.add chr res lex.cmap }
| _ -> lex
in loop lex (InputModule.explode str)
let len lex =
let rec loop lex n =
CharMap.fold (fun _ -> loop) lex.cmap (n + if lex.flag then 1 else 0)
in loop lex 0
let sub str lex =
let rec loop lex = function
| [] -> lex
| chr :: t when CharMap.mem chr lex.cmap ->
let res = loop (CharMap.find chr lex.cmap) t in
{ flag = false; cmap = CharMap.add chr res CharMap.empty}
| _ -> raise Not_found
in loop lex (InputModule.explode str)
end
module Latin1 = Make (
struct
type t = char
let compare = Char.compare
let explode str =
let rec loop acc = function
| 0 -> acc
| i -> let j = i - 1 in loop (str.[j] :: acc) j
in loop [] (String.length str)
end )
module UTF_8 = Make (
struct
type t = Glib.unichar
let compare = compare
let explode str = Array.to_list (Glib.Utf8.to_unistring str)
end )
|


Les sources présentées sur cette page sont libres de droits
et vous pouvez les utiliser à votre convenance. Par contre, la page de présentation
constitue une œuvre intellectuelle protégée par les droits d'auteur. Copyright ©
2009 Edouard Evangelisti. Aucune reproduction, même partielle, ne peut être
faite de ce site ni de l'ensemble de son contenu : textes, documents, images, etc.
sans l'autorisation expresse de l'auteur. Sinon vous encourez selon la loi jusqu'à
trois ans de prison et jusqu'à 300 000 € de dommages et intérêts.